
科技改變生活 · 科技引領未來
科技改變生活 · 科技引領未來

信道編碼方案是5GNR接入技術的基本問題之一。作為NR-eMBB方案的候選方案,提出了三種信道編碼方案,即Polarcode,Turbocode和LDPCcode。在本文中,主要接受華為給出的三種信道編碼方案的性能比較結果。Polarcod
信道編碼方案是5G NR接入技術的基本問題之一。作為NR-eMBB方案的候選方案,提出了三種信道編碼方案,即Polar code, Turbo code 和 LDPC code。在本文中,主要接受華為給出的三種信道編碼方案的性能比較結果。
Polar code是基于信道極化的可證明容量實現碼。Polar code的構造方法在R1-164309和
R1-167209中有詳細介紹,由于Polar code的嵌套結構,Polar code很容易支持任意的編碼速率和信息長度。除了簡單的SC解碼器外,CA-SCL解碼器也可以達到很好的性能。
LDPC碼有兩種方法。首先,為了支持多速率,需要準備許多LDPC碼的協議,以降低在發送端過多的穿孔所帶來的復雜性,同時還要考慮這些協議的存儲。第二,采用嵌套矩陣,支持多速率。然而,嵌套矩陣具有較小的提升尺寸,導致高編碼/解碼復雜度和性能下降。另外,對于這兩種方法,PCM:parity check matrix(奇偶校驗矩陣)應設計為簡單的速率自適應和HARQ方案。
這里對極性碼和LDPC碼的性能進行了比較,并在eMBB情況下增加了LTE-turbo性能,以供參考。先看兩張模擬參數表:
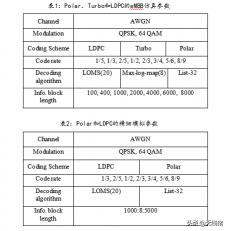
根據這兩個模擬假設,模擬了一組富塊長度和碼率組合。Polar code的譯碼算法是CA-SCL32。對于LDPC,譯碼算法采用了20次迭代的最小和分層,這里采用了Samsung在R1-164812中LDPC的奇偶校驗矩陣和相應的最小和分層譯碼算法的歸一化值。對于turbo,它是max-log-map,比例=0.75,迭代次數是8。在模擬過程中,對于所有信息長度的Turbo碼和LDPC碼不添加CRC位,對于信息長度為100和400的Polar code,添加8位CRC位。對于Polar code的其他情況,使用24位CRC。
調制 Modulation = {QPSK}
Modulation = {64 QAM}
對于R1-164812中給出的11n-like 嵌套矩陣,通過縮短和屏蔽1/3奇偶校驗矩陣,可以獲得高于1/3的編碼率。因此,對于較高的編碼速率(例如1/2和2/3),性能損失比編碼速率1/3的性能損失更大。
從圖1和圖2可以看出,在編碼速率為1/3時,與Polar相比,性能損失約為0.2-0.4dB。然而,對于編碼率1/2和2/3,損耗大約為1dB。
對于低于1/3的編碼率,之前只是從1/3奇偶校驗矩陣中重新傳輸部分編碼比特。因此,對于編碼率低于1/3的情況,將沒有編碼增益。
此外,對于QPSK和64-QAM,LDPC和Turbo碼的性能損失與Polar碼的性能損失趨勢相同。
結論是:Polar 和Turbo碼在所有碼率下都優于11n-like-LDPC碼。Polar 在所有碼率和塊長上都比Turbo碼和11n-like-LDPC碼有更好的性能。
細粒度性能比較
Modulation = {QPSK}
為了支持類似于LTE中Turbo粒度的細粒度,應該仔細設計嵌套矩陣,以避免某些代碼長度導致性能急劇下降。如圖3所示,這些糟糕的性能點往往發生在低編碼率區域。對于極高的編碼速率區域,LDPC code有大約0.2-0.4dB的性能損失和更多的波動點。
下面給出了更多的細粒度模擬結果。
從圖4、圖5和圖6可以看出,在編碼率為1/3時,存在一些比編碼率為5/6時性能損失更大的缺點。然而,在編碼率為5/6時,有更多的波動點。在圖5中,與Polar碼相比,LDPC碼在所有信息長度上都有大約1dB的性能損失。
結論是:為了支持細粒度,LDPC可能有一些性能急劇下降的缺點,這意味著應該仔細設計縮短和穿孔方案。Polar碼沒有這樣的問題。
關于Polar解碼器的設計,有如下方案:
SC list (SCL) decoding :SC解碼器通過在每個解碼步驟保持候選列表來概括SC解碼,其中列表大小為L。在列表解碼期間,保留具有最佳路徑度量的L條路徑。最后,選擇具有最佳路徑度量的路徑作為最終解碼結果。
SC stack (SCS) decoding:stack譯碼器是SC譯碼器的另一個推廣,與SCL類似,它在譯碼過程中產生了許多候選碼。不同之處在于,SCS不是保持所有候選路徑的長度相同,而是開發具有最可能路徑的路徑。如果某個長度的路徑數達到L,則從堆棧中刪除所有較短的路徑。當L被設置為與SCL中的相同并且使用足夠大的Q時,SCS具有與SCL相同的性能。
由于分割率很低,解碼路徑通常不需要推送到隊列或從隊列中彈出,這意味著一種高度并行的內存組織和高效率的PE利用率。在這種情況下,解碼路徑的行為與獨立SC解碼器相同。這種類型的多個路徑可以并行開發,如下圖所示
在框圖中,有八個并行處理單元,每個并行處理單元包含用于存儲LLR表的RAM單元和用于計算LLR的處理元件(PE: processing element)。如果處理單元到達一個分割點,新生成的兩條路徑將被推送到優先級隊列中。同時,緩沖器中的路徑將被填充到空出的處理單元中以進行進一步處理。隨后,將彈出一條具有最佳路徑度量的路徑來填充路徑緩沖區。這樣,在等待隊列操作的結果時,PE將永遠不會空閑。
極Polar解碼器最消耗的區域是存儲路徑度量和LLR表,它們占據了大約80%的RAM。華為給出的數據證明,在適當的重新設計下,它們可以大大減少。
新的路徑度量:可以利用先驗知識和后驗知識來定義一個在PPD(Prioritized parallel decoder)中更有效的路徑度量。該先驗知識用于補償路徑擴展過程中的平均代價。改進的路徑度量不僅加快了譯碼速度,而且大大減小了所需的優先級隊列大小Q。
LLR表存儲:在SCL中,LLR表是最消耗空間的部分。與SCL需要L個并行處理單元(包括RAM和PE)不同,PPD只需要 l個并行處理單元(l

李書